MIT 알고리즘 개론 - 1. 알고리즘이란?
이 수업의 목표
- 컴퓨터적 문제(Computational Problem)를 해결한다.
- 알고리즘의 정확성을 증명할 수 있다.
- 알고리즘의 효율성을 논의할 수 있다.
- 만든 알고리즘의 정확성과 효율성을 다른 사람들과 소통할 수 있는 방법을 배운다.
본 알고리즘 수업은 사실 CI(Communication Intensive; 학생들이 구두나 서면으로 효과적으로 의사소통하는 능력을 향상시키기 위한 MIT의 교육 요구사항) 수업이라고 봐도 무방하다. 코딩하는 시간보다 글 쓰는 시간이 더 많을거다. 이론 수업처럼 이 수업은 알고리즘이 정확한지, 다른 방법보다 더 효율적인지 증명하는 걸 더 중요하게 생각한다. 그제서야 다른사람과 소통할 수 있고, 맞다고 설득할 수 있기 때문이다.
컴퓨터적 문제(Computational Problem)란?
문제란, 입력과 출력이 연결된 이항관계이다. 아래처럼 입력과 출력이 서로 매핑되어 있고, 한 입력에 여러 출력이 연결될 수 있다. 일종의 이분 그래프라고 볼 수 있다.
이때 입력을 인스턴스(Instance)또는 케이스라고 부르기도 한다.
 입력과 출력간의 이항관계
입력과 출력간의 이항관계
그러나 대부분의 경우엔 입력의 수가 엄청 많고, 이 경우엔 출력을 일일이 대응하기 어렵다. 그래서 일반적인 방법으로 출력이 맞는지 확인할 수 있는 술어(Predicate)를 사용한다.
예를들어, "1, 3, 5, 7, 9, 10 중 짝수가 있는가?"는 작은 크기의 입력만 대응한다. 이를 좀 더 일반적으로 표현해보면 "주어진 n개의 숫자 중 짝수가 있는가?", 어떤 크기의 입력이든 상관 없다.
알고리즘(Algorithm)이란?
알고리즘은 입력을 받아 출력을 만들어내는 절차다. 좀 더 쉽게 말하면, 입력을 넣으면 출력이 나오는 함수다. 이때 매 입력마다 똑같은 출력이 나와야한다. (이런 특징을 Deterministic이라고 한다.)
알고리즘이 문제를 푼다는 건, 문제의 입력에 올바른 출력을 돌려주는거다. 즉, 알고리즘 자체로는 만들어낸 출력이 맞는지 판단할 수 없다. 그저 정해진 절차에 따라 입력을 요리조리 굴려서 출력을 만들어낼 뿐이다.
예를 들어 위에서 정의한 문제를 해결하는 알고리즘을 만들어보자.
문제: 주어진 n개의 숫자 중 짝수가 있는가?
알고리즘:
1. 숫자 n개를 입력받는다.
2. 숫자를 하나씩 살펴본다.
- 만약 해당 숫자가 2로 나누어 떨어진다면, 짝수가 있다고 돌려주고(참) 알고리즘을 종료한다.
- 아니라면 무시한다.
3. 숫자를 다 살펴봤지만, 아직 알고리즘이 종료되지 않았다. 짝수가 없다고 돌려주고(거짓) 알고리즘을 종료한다.
근데 이 알고리즘이 과연 정확할까? 과연 효율적일까?
알고리즘의 증명
알고리즘의 크기는 유한하다. 반면 입력은 매우 클 수 있다. 따라서 모든 알고리즘은 특정 명령을 반복하는 구조다. 이런 특성을 이용해 알고리즘의 증명에는 귀납법(Induction)을 사용한다.
귀납법의 간단한 예는 다음과 같다.
1. 도미노를 쓰러트리면 쓰러진다. (바탕 명제)
2. 쓰러진 도미노가 다른 도미노를 쓰러트린다.
따라서 첫번째 도미노를 쓰러트리면 모든 도미노가 쓰러진다는게 분명하다.
위 알고리즘을 예로 들어보자.
- 가설: 번째 숫자까지 살펴봤을 때 짝수가 있다면 번째 숫자를 보기 전 (참)를 돌려준다.
- 바탕 명제(Base case): , 주어진 숫자가 없으므로 무조건 가설이 성립한다.
- 에 대하여 성립한다는 가정 아래, 이 성립하는가?
- 가 성립하므로, 번째까지 숫자 중 이미 짝수가 있을 경우 이미 를 돌려줬을 것이다.
- 만약 없을 경우, 번째 숫자가 짝수인지 체크한다.
- 따라서 에 대해서도 성립한다.
위 내용은 좀 형식적이고, 간단하게 말해보자면 아래와 같다.
- n + 1번째 숫자를 검사한다는 건, n개의 숫자를 이미 검사했는데 그 중 짝수가 없었다는 말이다.
- n + 1번째 숫자가 짝수라면 참을 돌려주면서 알고리즘이 끝나고, 아니라면 계속 진행한다.
- 따라서 해당 알고리즘은 모든 숫자에 대해서 짝수의 유무를 찾아낼 수 있는 게 자명하다.
알고리즘의 효율성
알고리즘이 얼마나 빠른지 측정하려면 어떻게 해야할까?
- 실행시간을 잰다: 좋지않음. 컴퓨터의 성능에 따라 천차만별이 될 수 있다.
- 알고리즘의 기초 연산이 몇번 일어나는지 센다. 즉, 입력값의 크기에 따른 실행 횟수의 차이를 센다: 성능에 영향을 받지 않는다. 성능 측정을 위한 알고리즘 구현체(코드)가 필요없다. 즉, 추상적으로 접근할 수 있다.
예를 들어 숫자 n을 넘겨주었을 때 별(*) 삼각형을 돌려주는 알고리즘의 연산을 세어보자.
수도코드:
read(n)
for (i = 1 to n) { // i는 1에서 n까지
for (j = 1 to i) { // j는 1에서 i까지
print("*")
}
}예를 들어 n이 5일때, 반복문의 내용이(위 예제의 경우 print) 총 1 + 2 + 3 + 4 + 5 = 15번 실행된다.
입력: n = 5
출력:
*
**
***
****
*****이는 등차수열 공식을 이용해 아래과 같이 일반화시킬 수 있다.
이 식은 항과 항의 합으로 이루어져 있다. 작은 크기의 입력일 때는 이 둘의 차가 크지 않지만, 매우 큰 입력은 차가 매우 커진다. 즉, 큰 입력에서 은 무의미해진다. 따라서 알고리즘의 실행 시간을 효과적으로 비교하기 위해선 이런 중요하지 않은 항과 상수, 계수를 모두 제거하는 점근적 표기법을 사용한다.
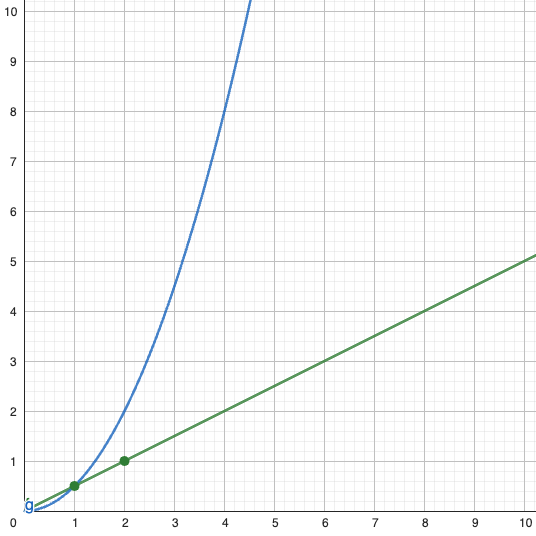 입력 값의 크기가 커질 수록 차이가 커진다
입력 값의 크기가 커질 수록 차이가 커진다
점근적 표기법의 종류엔 빅세타(), 빅오(), 빅오메가() 표기법이 있다.
- 빅오(): 상한에 근접하는 표기법이다. 최악의 경우를 생각할 때 사용된다.
- 빅오메가(): 하한에 근접하는 표기법이다. 최상의 경우를 생각할 때 사용된다.
- 빅세타(): 상한과 하한에 모두 근접하는 표기법이다. 정확한 실행 시간을 나타낼 떄 사용된다.
위 예제의 경우 이다.
점근적 표기법에 관한 좀 더 자세한 설명은 칸아카데미를 참고하자.
WordRAM 모델
알고리즘의 성능을 측정하기 위해서는 컴퓨터가 고정된 시간 안에 어떤 연산을 할 수 있는지 알아야한다. 그래서 해당 수업에서는 WordRAM 계산 모델을 사용한다.
WordRAM 모델은 Word와 RAM의 합성어다. RAM은 Random access memory로 무작위로 원하는 위치의 데이터를 고정된 시간 안에 가져올 수 있다. 메모리는 많은 정보를 기억할 수 있는 반면, CPU는 적은 정보를 기억하는 대신 이 정보들을 더하거나 빼는 등 연산할 수 있다. 이 CPU에 저장할 수 있는 정보의 크기가 Word인 데, 보통 32비트, 64비트 크기다. 그리고 Word의 크기만큼 메모리를 쪼개서 주소를 지정한다.
CPU는 O(1)의 고정된 시간 내에 할 수 있는 여러 연산을 제공한다.
- 정수 산술:
+, -, *, /, % - 논리 연산자:
&&, ||, !, ==, <, >, <=, >= - 비트 연산자:
&, |, ^, !, <<, >>, ... - 특정 주소의 메모리에 워드를 쓰고 읽기
자료구조
자료구조는 가변적인 데이터를 저장하고 여러 연산을 지원한다. 이 연산들은 WordRAM 모델에서 기본적으로 지원하지 않지만, 기본 연산들을 조합해 만들 수 있다.
이 연산들의 모음을 인터페이스라고 한다. 같은 인터페이스를 구현한 자료구조더라도 성능이 서로 다를 수 있다.
다음 강의에서는
앞으로 8개의 강의 동안에는 자료구조에 대해 얘기한다. 다음 강의는 '가변적인 정보를 빠르게 저장하는 여러가지 방법'에 대해 알아본다.